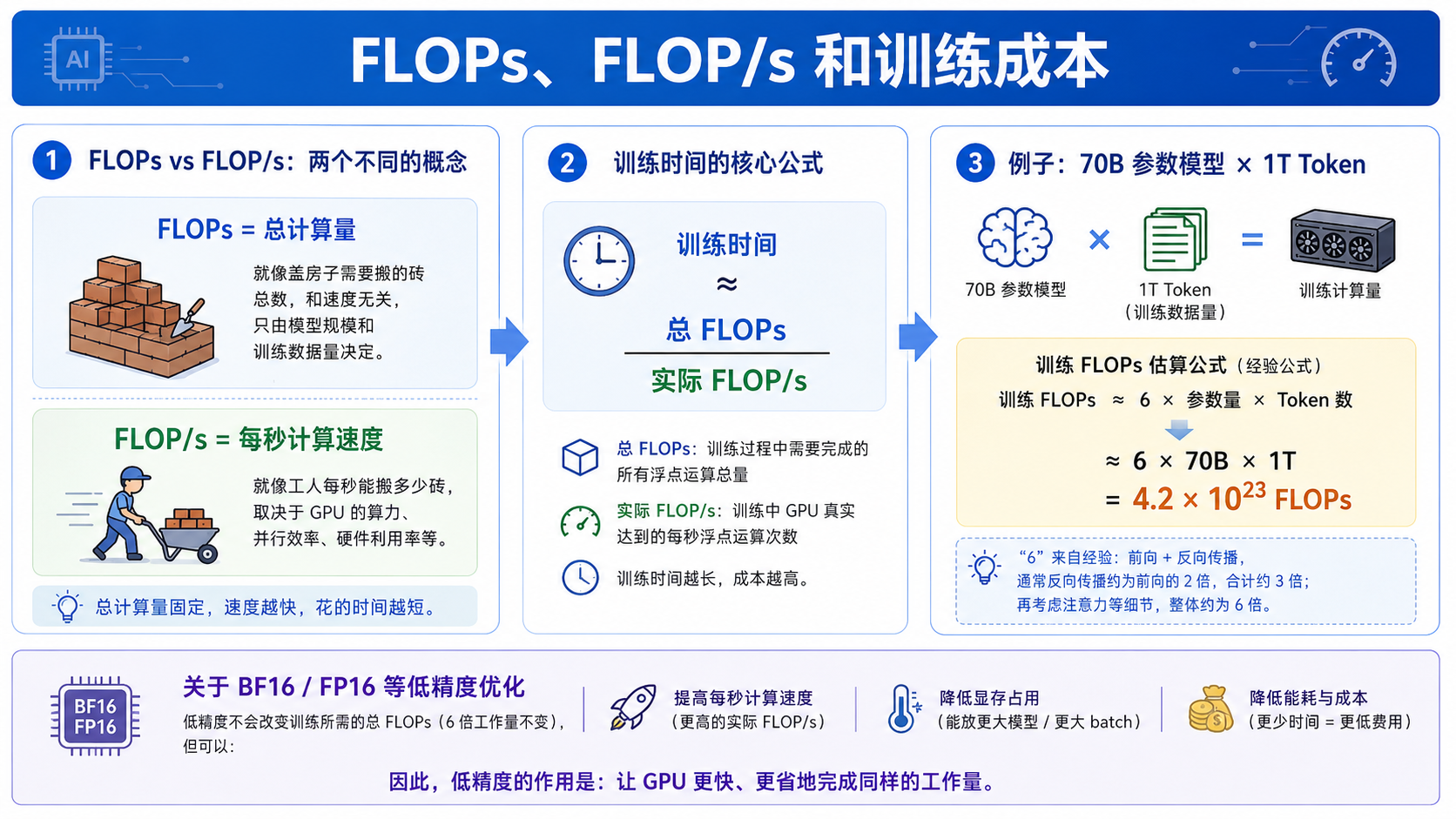
大模型训练的“6倍法则”
大模型训练的“6倍法则”
很多人看大模型训练成本时,经常会看到一个公式:
训练 FLOPs ≈ 6 × 参数量 × Token 数
70B 模型、1T Token、几百张 GPU、训练几十天……这些数字背后,几乎都绕不开这条经验公式。
但很多人第一次看到时都会困惑:
- 这个 6 到底从哪来?
- 它是在算 显存,还是在算 训练速度?
- 为什么不是 2,也不是 4?
答案是:
这条公式估算的是 训练总计算量,也就是训练过程中总共要做多少次浮点运算。
一、先搞清楚:FLOPs 不是 GPU 速度
FLOPs 是什么?
FLOPs = Floating Point Operations = 浮点运算次数
它描述的是:
一共要做多少计算。
你可以把它理解成“总工作量”。
比如:
- 一次乘法,可以粗略记作 1 次 FLOP
- 一次加法,也可以粗略记作 1 次 FLOP
所以,FLOPs 回答的是这个问题:
这个模型训练,总共要算多少次?
FLOP/s 又是什么?
FLOP/s = 每秒浮点运算次数
它描述的是:
硬件每秒能完成多少计算。
如果用一个更生活化的比喻:
| 概念 | 更容易理解的类比 |
|---|---|
| FLOPs | 一共有多少砖要搬 |
| FLOP/s | 每秒能搬多少砖 |
所以:
FLOPs 说的是工作量,FLOP/s 说的是速度。
训练时间大致可以写成:
训练时间 ≈ 总 FLOPs ÷ 实际 FLOP/s
也就是说,6 × 参数量 × Token 数 不是在说“跑得多快”,而是在说“活有多少”。
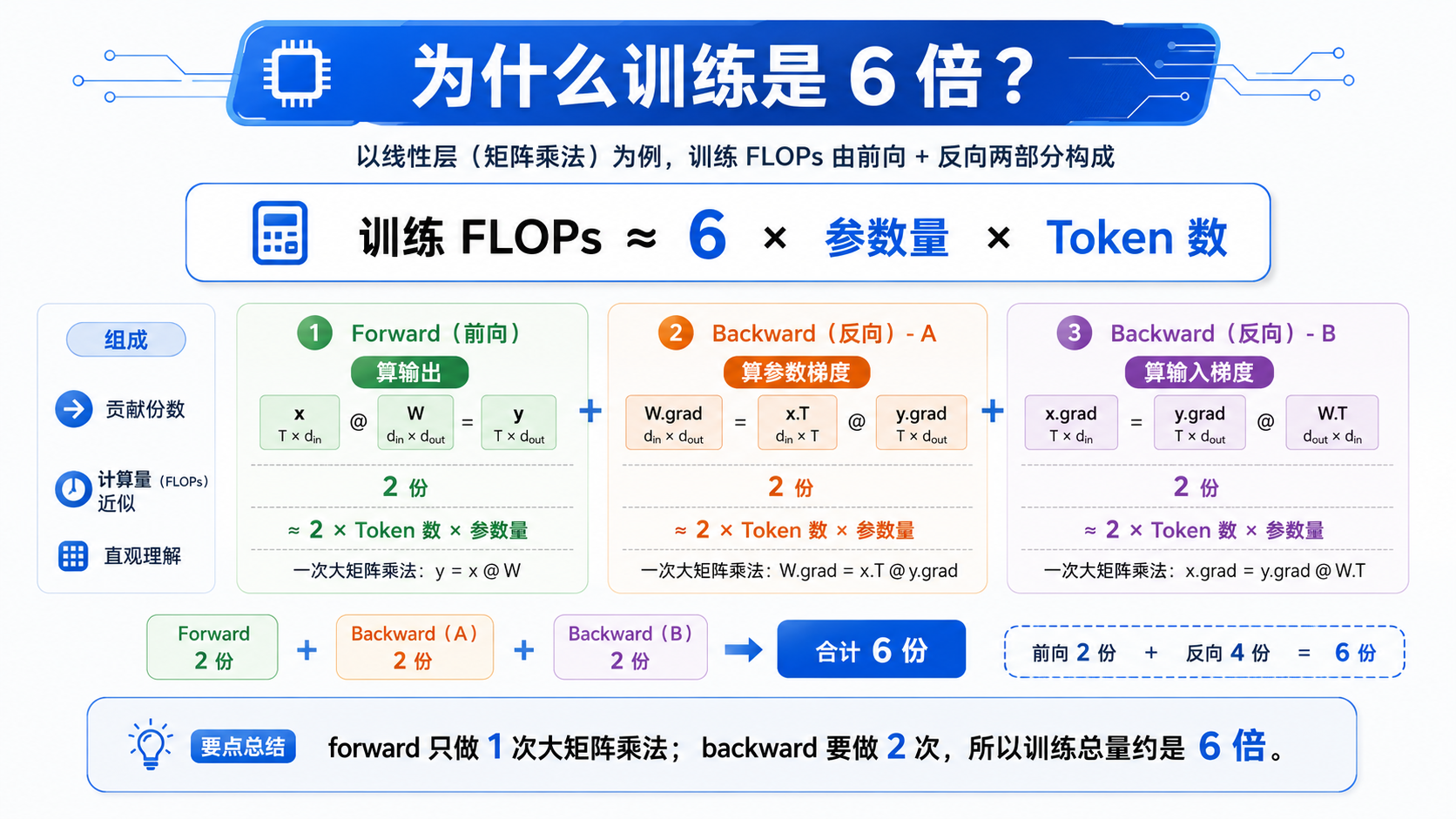
二、从一个最简单的 Linear 层开始
大模型里最耗算力的操作,本质上大多都是 矩阵乘法。
先看一个最简单的线性层:
y = x @ W
假设:
x的 shape 是(B, D)W的 shape 是(D, K)y的 shape 是(B, K)
这里可以这样理解:
B:Token 数D:输入维度K:输出维度W:模型参数
于是,参数量就是:
参数量 = D × K
三、为什么前向传播是 2 份?
前向传播只做一件大事:
算输出 y = x @ W
矩阵乘法里的每个输出元素,本质上都是一个点积。
也就是说,对于每个输出位置,都会发生:
- 若干次乘法
- 若干次加法
粗略估算时,我们通常把它近似写成:
一次乘法 + 一次加法 ≈ 2 FLOPs
因此,前向传播的计算量大约是:
forward FLOPs ≈ 2 × B × D × K
又因为:
B = Token 数D × K = 参数量
所以可以写成:
forward FLOPs ≈ 2 × Token 数 × 参数量
这就是为什么大家常说:
前向传播占 2 份。
四、为什么反向传播是 4 份?
训练和推理最大的区别在于:
- 推理只需要前向传播
- 训练还需要反向传播
而反向传播里,通常要额外计算两类梯度。
1)参数梯度
第一件事,是计算参数的梯度:
W.grad = x.T @ y.grad
它的含义是:
loss 对参数 W 的梯度是多少?
这个矩阵乘法的计算量,和 forward 是同一个量级:
≈ 2 × Token 数 × 参数量
2)输入梯度
第二件事,是把梯度继续传回上一层:
x.grad = y.grad @ W.T
它的含义是:
loss 对输入 x 的梯度是多少?
为什么这一步也必须算?
因为大模型不是只有一层 Linear,而是一层接一层。如果不把梯度继续往前传,前面的层就没法更新。
这一步的计算量同样大约是:
≈ 2 × Token 数 × 参数量
所以,反向传播总共是:
- 参数梯度:2 份
- 输入梯度:2 份
合起来就是:
backward FLOPs ≈ 4 × Token 数 × 参数量
也就是:
反向传播占 4 份。
五、为什么最后会变成 6 倍?
把前向和反向加在一起:
| 阶段 | 近似计算量 |
|---|---|
| Forward | 2 × Token 数 × 参数量 |
| Backward | 4 × Token 数 × 参数量 |
| 合计 | 6 × Token 数 × 参数量 |
因此,训练总 FLOPs 通常可以近似写成:
训练 FLOPs ≈ 6 × 参数量 × Token 数
这个 6 不是玄学,也不是拍脑袋,而是从一个线性层的矩阵乘法 forward/backward 推出来的。
更直白一点:
forward 做 1 次大矩阵乘法,backward 做 2 次,所以总量约是 6 份。
六、一个具体例子:70B 模型到底有多贵?
假设一个模型有:
- 参数量 = 70B
- 训练数据 = 1T Tokens
那么训练计算量大约就是:
6 × 70B × 1T = 4.2 × 10^23 FLOPs
这意味着什么?
这不是一个“有点大”的数字,而是一个天文级数字。
也正因为如此,大模型训练才会:
- 需要大量 GPU
- 训练时间很长
- 电力和机器成本都非常高
换句话说:
大模型训练不是简单“把数据喂一遍”,而是每个 Token 都要在巨大的参数矩阵上反复做乘加计算。
七、BF16 / FP16 会改变这个 6 倍吗?
很多人会继续问:
如果我用了 BF16、FP16、Tensor Core,这个 6 倍会不会变小?
一般来说:
不会。
原因很简单:
6 × 参数量 × Token 数描述的是 总工作量- BF16 / FP16 / Tensor Core 优化的是 完成这份工作量的速度
也就是说,低精度优化通常不会让“要干的活变少”,而是让 GPU:
- 算得更快
- 吞吐更高
- 显存更省
- 成本更低
所以你可以这样记:
6 倍公式:决定工作量
低精度优化:提升速度与效率
同样一堆砖,低精度不是让砖变少,而是让你搬得更快。
八、这个公式是不是精确到每一个算子?
也不是。
它是一个非常有用的 经验估算公式,适合帮助我们快速判断训练成本的数量级。
真实训练里,除了矩阵乘法,还会有很多其他开销,比如:
- Attention score
- Softmax
- LayerNorm
- 激活函数
- Dropout
- Embedding
- 优化器更新
- 通信开销
- 显存读写
但在大模型里,矩阵乘法通常占据主要计算量,所以:
训练 FLOPs ≈ 6 × 参数量 × Token 数
依然是一个非常实用的近似公式。
它特别适合用来理解这些问题:
- 模型为什么越大越贵?
- Token 为什么越多越贵?
- 训练为什么比推理贵很多?
九、最后总结
把整篇文章压缩成一句话:
大模型训练的“6倍法则”,本质上来自线性层矩阵乘法的 forward 和 backward。
你可以把它记成下面这张“账单”:
- 前向传播:算输出,占 2 份
- 反向传播:算参数梯度,占 2 份
- 反向传播:算输入梯度,占 2 份
所以最终:
训练 FLOPs ≈ 6 × 参数量 × Token 数
理解了这个公式之后,你再去看大模型训练成本,就不会只停留在“参数很多”“GPU 很贵”这种模糊印象上。
你会更清楚地知道:
每一个 Token,都要穿过巨大的参数矩阵;
每一次训练,不仅要算答案,还要把误差反向传回去。
这,就是大模型训练真正烧钱的地方。