大模型的核心,竟然只是矩阵乘法?
大模型的核心,竟然只是矩阵乘法?
今天我们经常听到这些词:
大模型、Transformer、Attention、GPU、CUDA、算力、训练、推理。
听起来都很高深。
但如果把这些概念一层一层拆开,你会发现一个很有意思的事实:
现代 AI 的核心计算,大量都是矩阵运算。
尤其是大语言模型 LLM,不管是前向推理,还是训练时的反向传播,本质上都离不开矩阵乘法。
而 GPU 之所以能成为 AI 时代的核心硬件,也是因为它特别擅长做大规模并行矩阵计算。
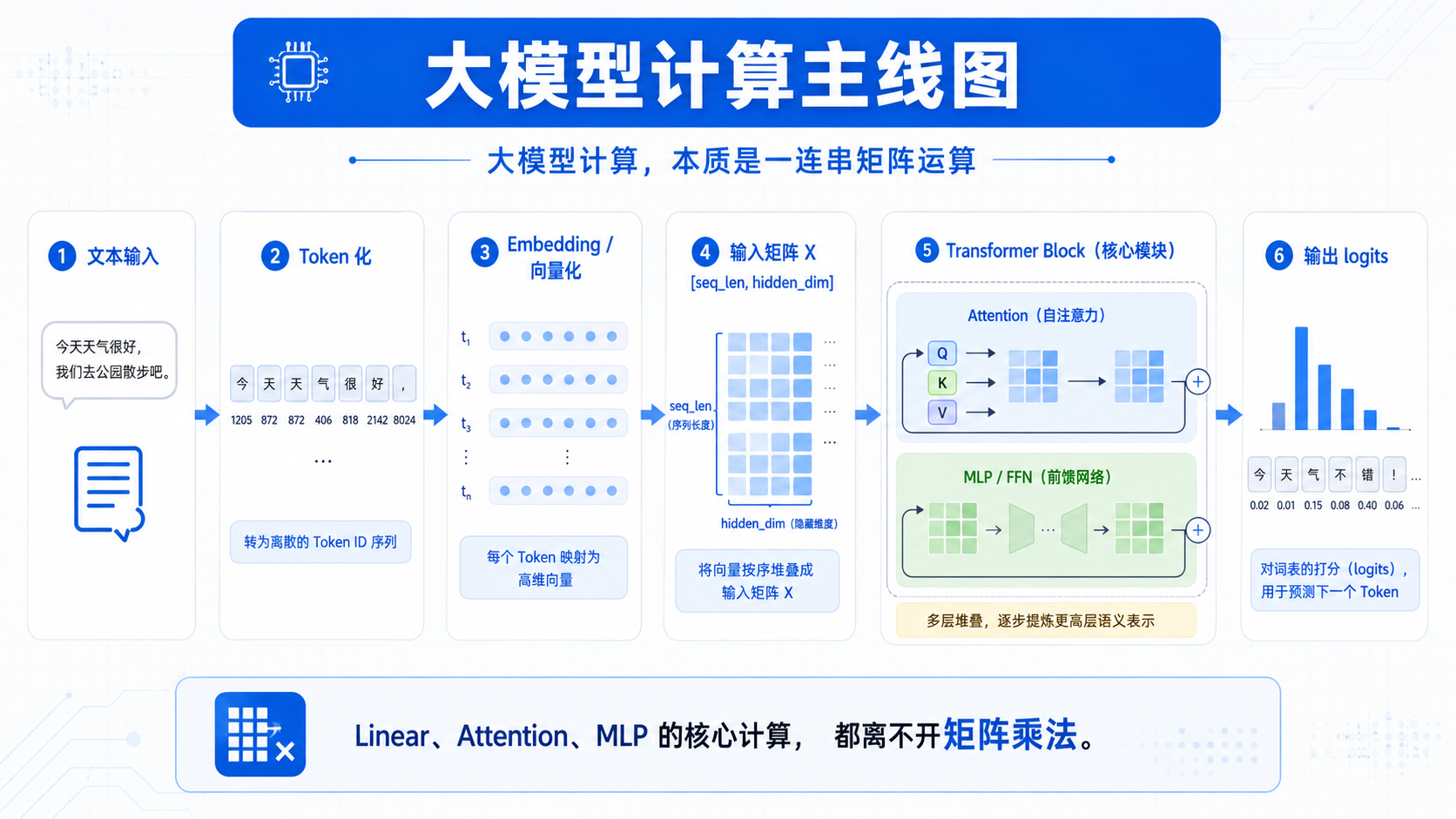
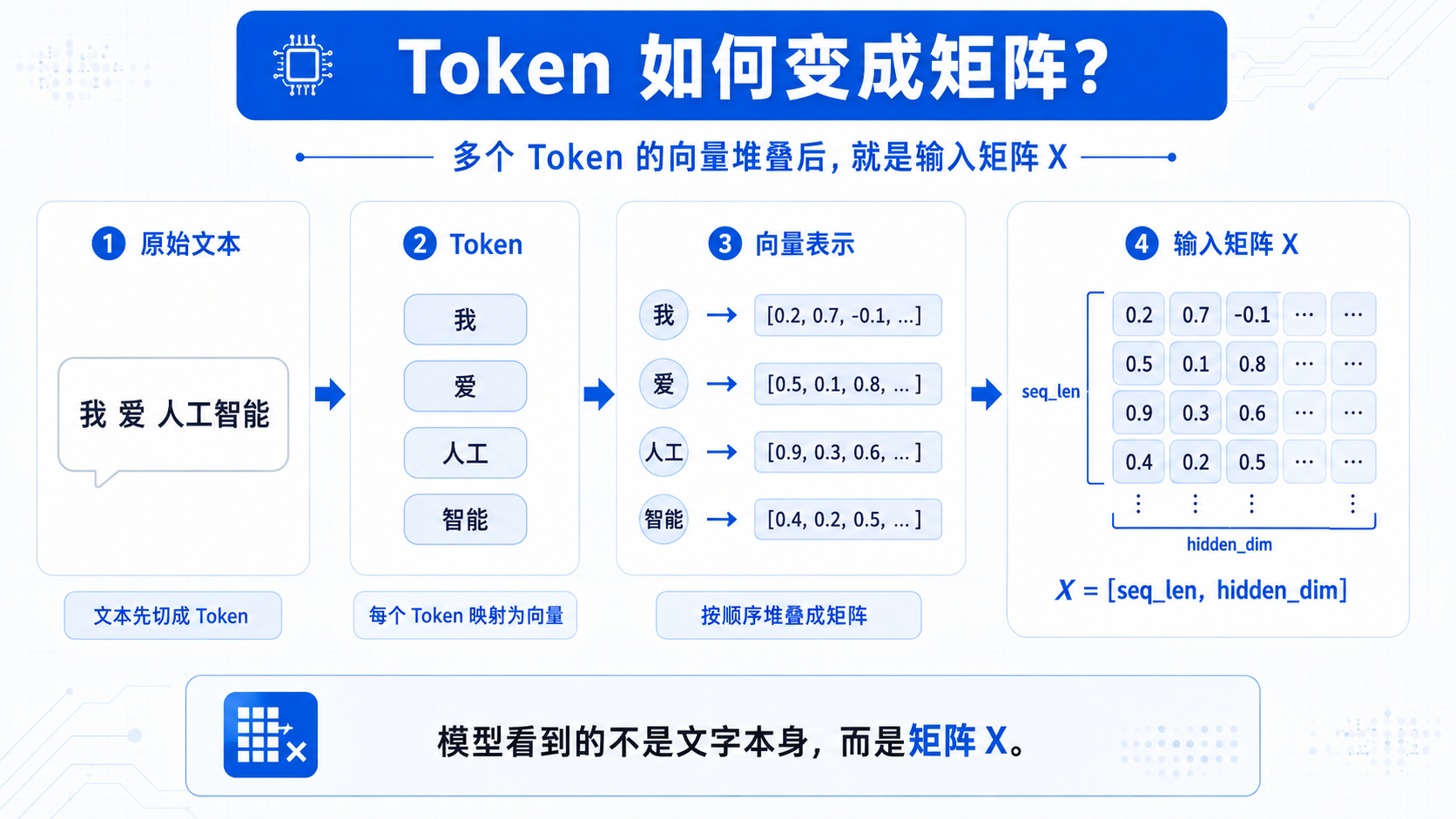
一、文本进入模型后,先变成矩阵
神经网络不能直接理解文字。
比如一句话:
我 爱 人工智能
进入模型后,每个 token 会先被转换成一个向量。
可以简单理解成:
我 → [0.2, 0.7, -0.1, ...]
爱 → [0.5, 0.1, 0.8, ...]
人工智能 → [0.9, 0.3, 0.6, ...]
一个 token 是一个向量。
多个 token 的向量堆叠在一起,就变成了一个矩阵。
例如:
X = [seq_len, hidden_dim]
如果一句话有 4 个 token,每个 token 用 768 维向量表示,那么:
X = [4, 768]
从这一刻开始,模型后面的计算几乎都围绕这个矩阵展开。
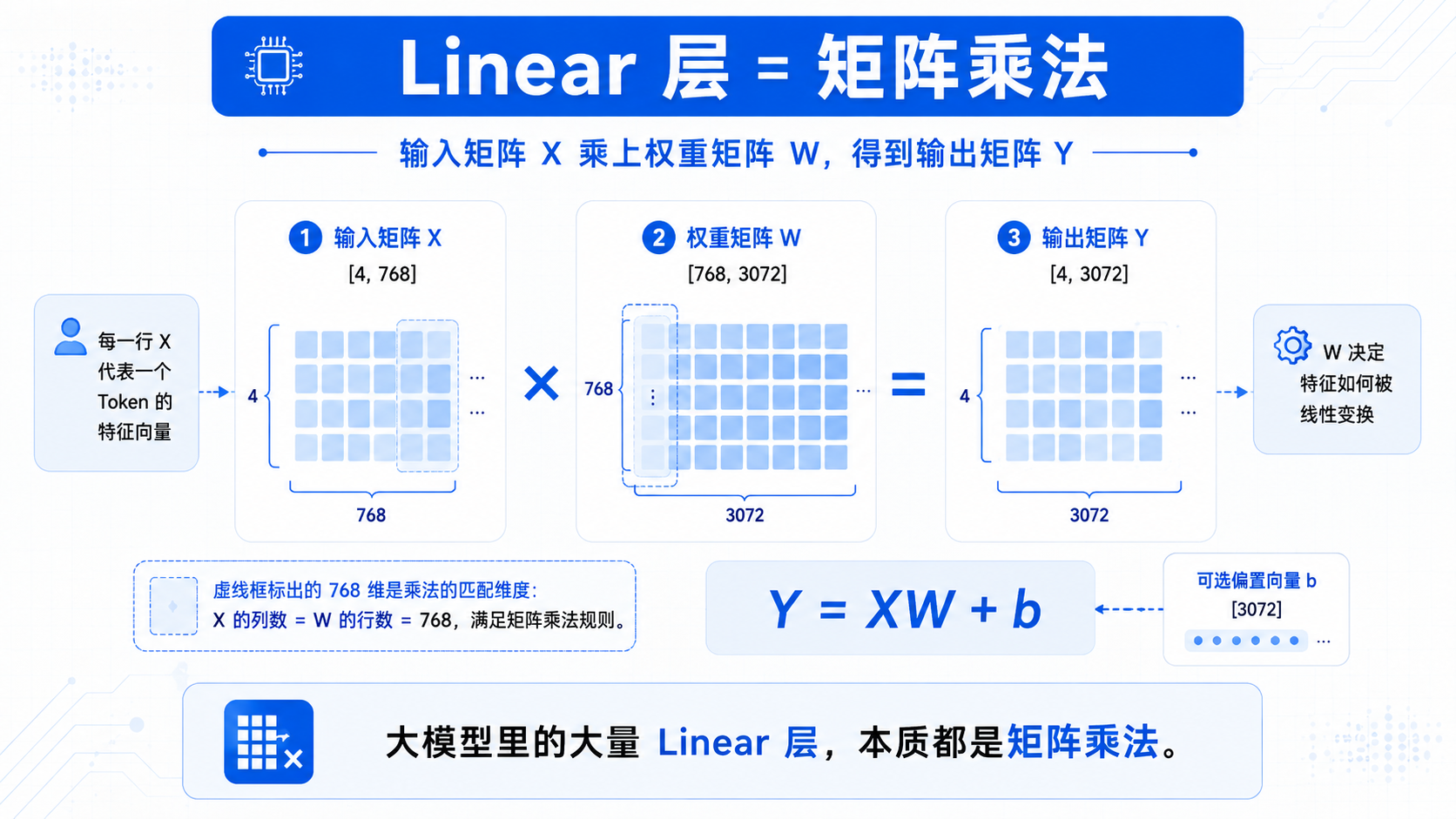
二、Linear 层就是矩阵乘法
神经网络里最常见的结构叫 Linear 层,也叫全连接层。
它的计算公式是:
Y = XW + b
其中:
X:输入矩阵
W:权重矩阵
b:偏置
Y:输出矩阵
比如:
X: [4, 768]
W: [768, 3072]
Y: [4, 3072]
这一步其实就是一次矩阵乘法。
输入矩阵 X 乘上权重矩阵 W,得到新的输出矩阵 Y。
大模型里有大量 Linear 层,所以大模型天然就是矩阵乘法密集型程序。
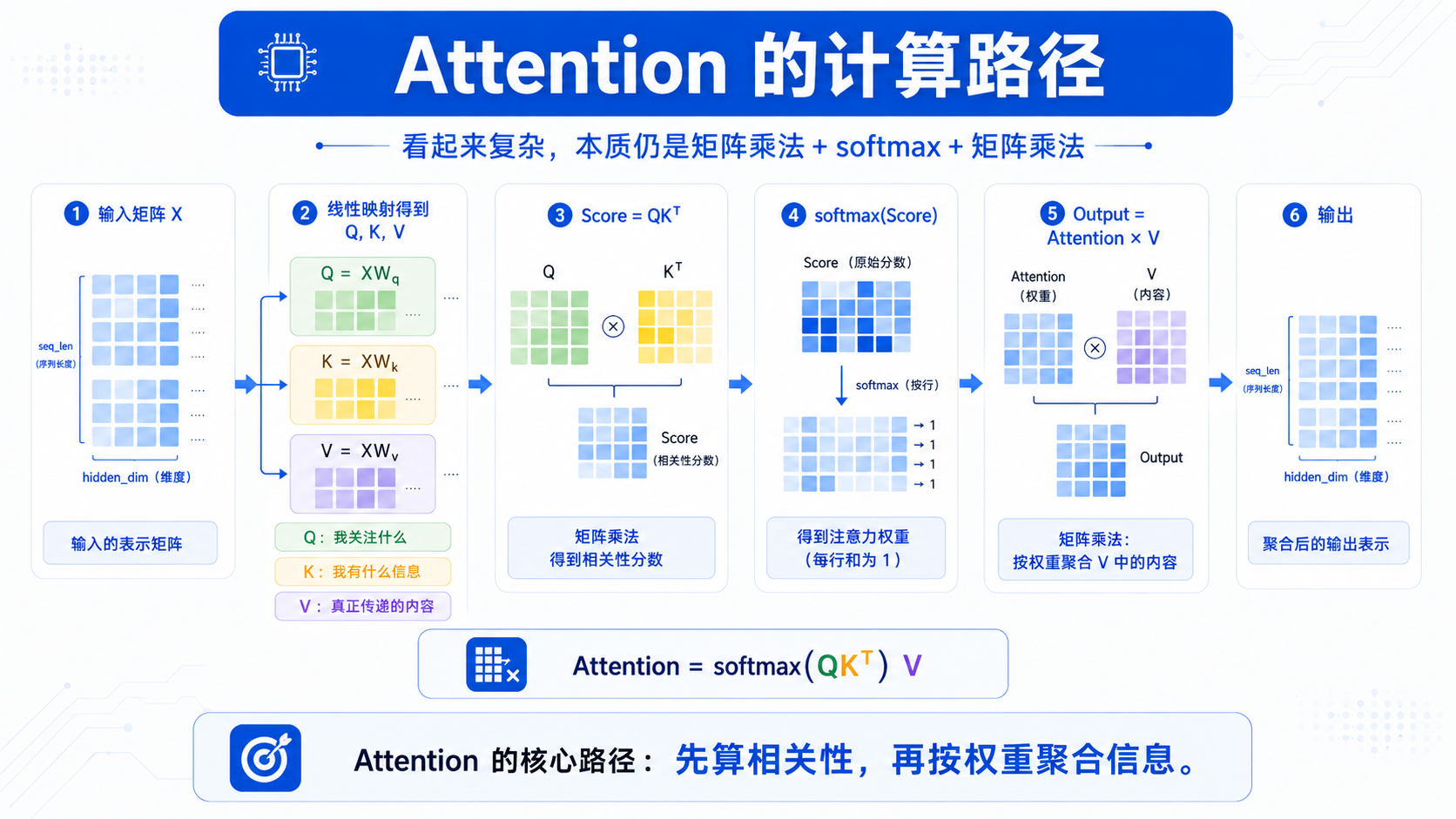
三、Attention 拆开后,也是矩阵运算
Transformer 最核心的模块是 Attention。
很多人觉得 Attention 很神秘,但它拆开以后,其实也是一组矩阵运算。
首先,输入矩阵 X 会分别乘上三个权重矩阵:
Q = XWq
K = XWk
V = XWv
也就是得到 Query、Key、Value 三个矩阵。
然后计算注意力分数:
Score = QKᵀ
这又是一次矩阵乘法。
接着经过 softmax 得到注意力权重:
Attention = softmax(Score)
最后再乘上 V:
Output = Attention × V
所以 Attention 的核心路径可以概括为:
X
↓
Q = XWq
K = XWk
V = XWv
↓
Score = QKᵀ
↓
softmax
↓
Output = Attention × V
看起来复杂,其实核心就是:
矩阵乘法 + softmax + 矩阵乘法
其中最耗算力的部分,仍然是矩阵乘法。
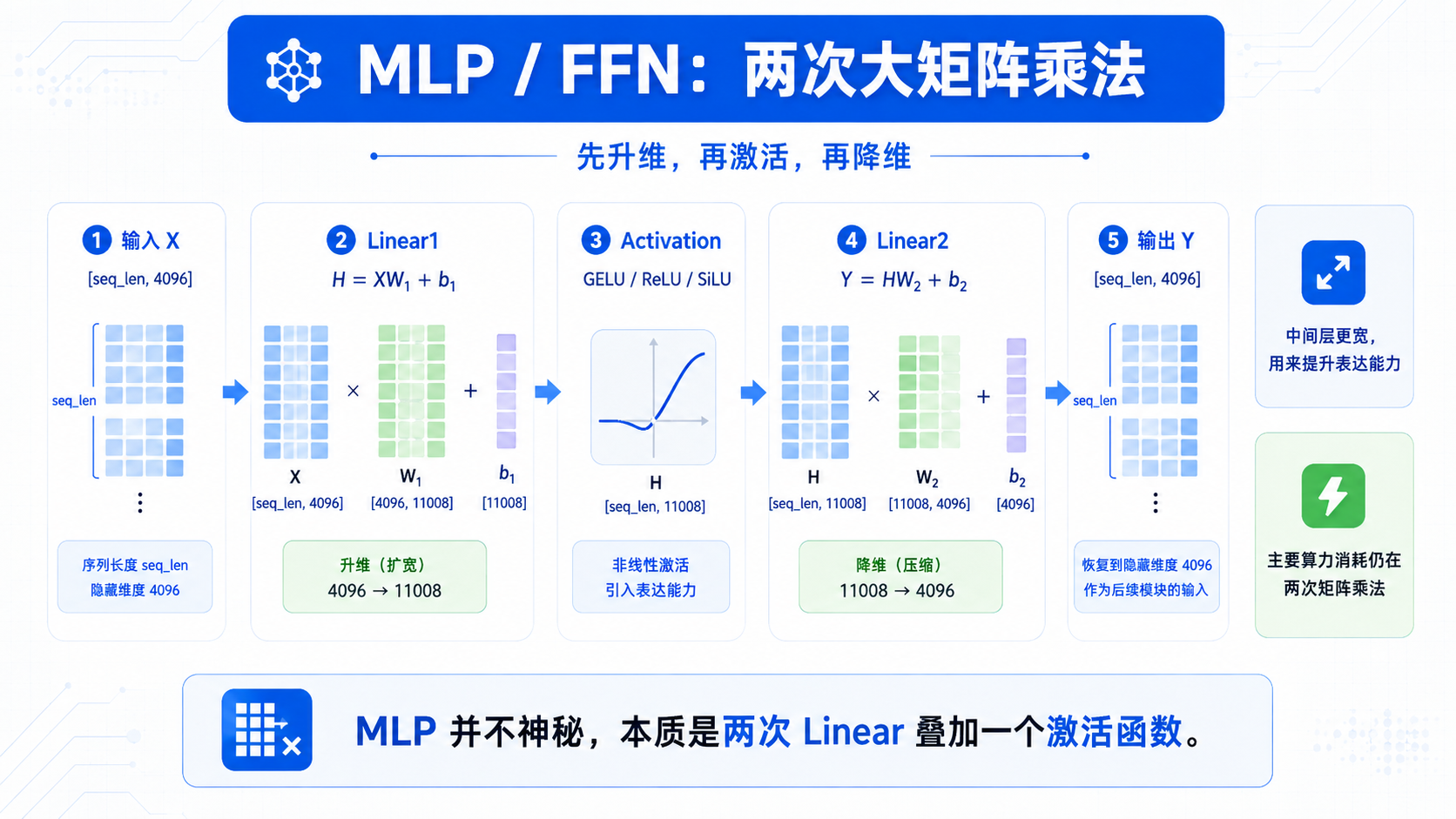
四、MLP / FFN 也是矩阵乘法
Transformer Block 里除了 Attention,还有一个非常重要的模块:MLP,也叫 FFN。
典型结构是:
Y = Linear2(Activation(Linear1(X)))
展开以后就是:
H = XW1 + b1
H = activation(H)
Y = HW2 + b2
比如 hidden_dim 是 4096,中间层扩展到 11008:
X: [seq_len, 4096]
W1: [4096, 11008]
H: [seq_len, 11008]
W2: [11008, 4096]
Y: [seq_len, 4096]
也就是说,MLP 的主要计算是两次大矩阵乘法:
第一次:升维
第二次:降维
所以一个 Transformer Block 里:
Attention:矩阵乘法
MLP:矩阵乘法
输出投影:矩阵乘法
再加上几十层、上百层堆叠之后,大模型的计算量就非常可观了。
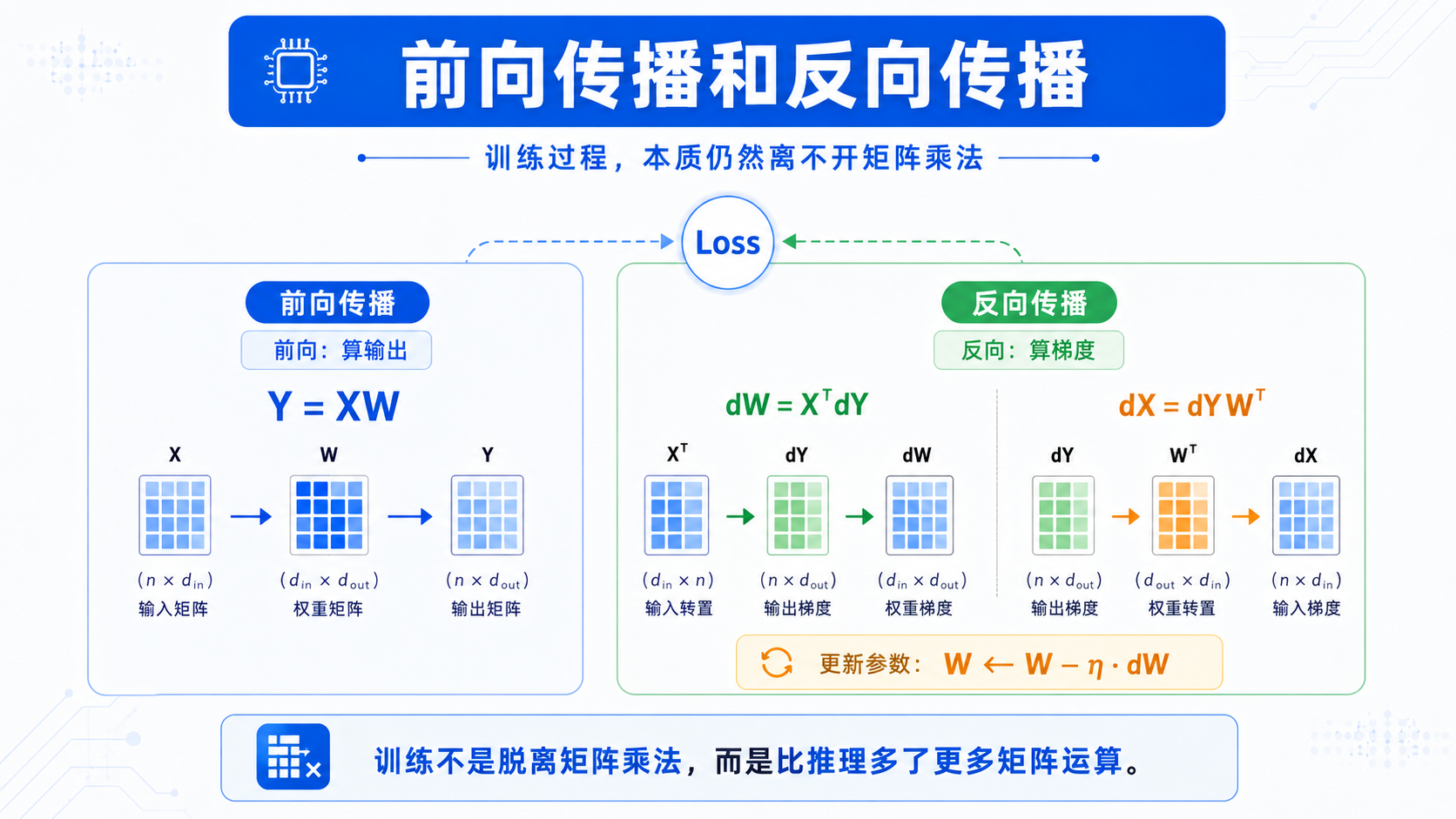
五、推理是矩阵运算,训练也是矩阵运算
前面讲的是模型前向传播。
也就是输入一个问题,模型输出答案。
但训练模型时,还需要反向传播。
很多人以为反向传播是另一套完全不同的东西,其实它的核心也离不开矩阵运算。
以最简单的 Linear 层为例:
Y = XW
假设损失函数对输出 Y 的梯度是:
dY
那么权重 W 的梯度是:
dW = XᵀdY
输入 X 的梯度是:
dX = dYWᵀ
你会发现:
dW = XᵀdY
dX = dYWᵀ
这两个仍然是矩阵乘法。
所以训练过程可以理解为:
前向传播:大量矩阵乘法
反向传播:大量矩阵乘法
参数更新:根据梯度更新矩阵
这就是为什么训练大模型需要极高算力。
因为训练不是只算一遍前向传播,而是还要计算大量梯度。
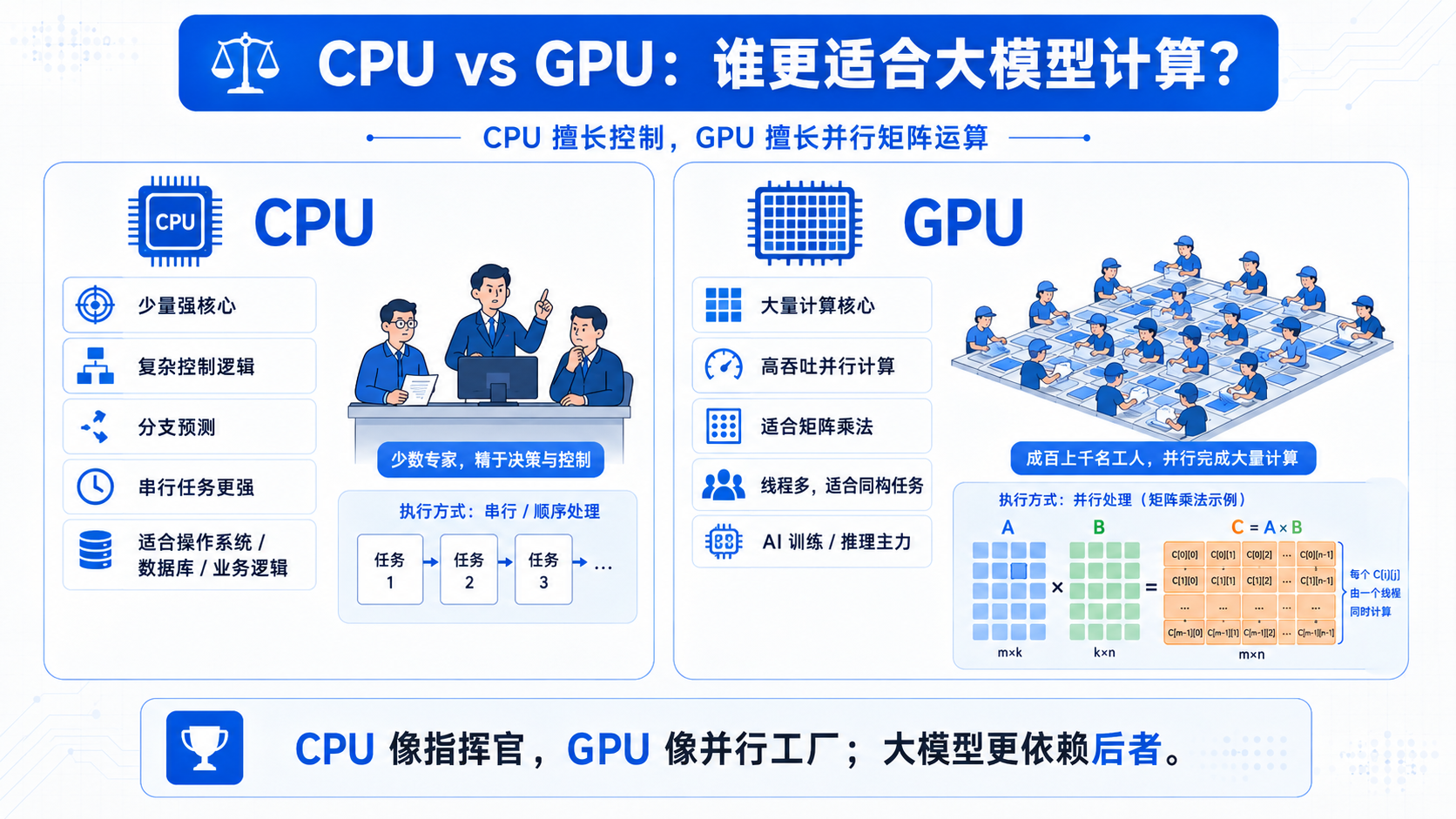
六、GPU 为什么特别适合 AI?
CPU 很强,但它更像一个“少量核心、每个核心很聪明”的处理器。
它擅长:
复杂逻辑
分支判断
任务调度
操作系统
数据库
业务程序
比如 CPU 里有很多硬件机制:
分支预测
乱序执行
复杂缓存
高单核性能
这些能力让 CPU 很适合处理复杂控制逻辑。
GPU 则不同。
GPU 更像一个“大量计算单元组成的并行工厂”。
它不擅长复杂分支,但特别擅长大量相似计算。
矩阵乘法刚好非常适合 GPU。
比如计算:
C = A × B
矩阵 C 里的每一个元素都可以相对独立地计算:
C[i][j] = A 的第 i 行 · B 的第 j 列
也就是:
C[i][j] = A[i][0]B[0][j]
+ A[i][1]B[1][j]
+ A[i][2]B[2][j]
+ ...
矩阵 C 有成千上万个元素,每个元素都可以分配给不同线程去算。
所以 GPU 的优势不是一个人算完整张表,而是一群线程同时算很多格子。
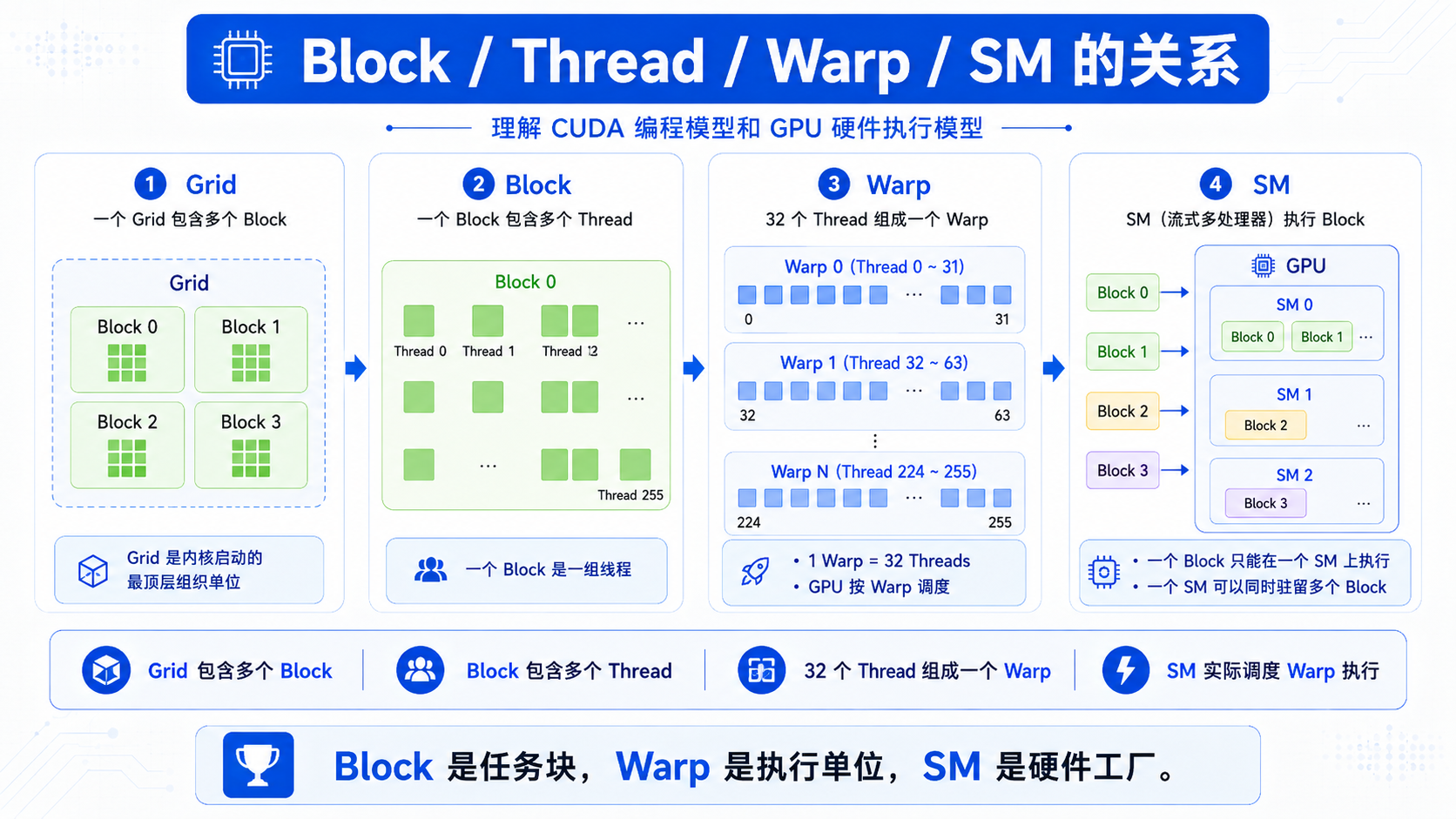
七、CUDA 怎么组织 GPU 并行?
在 CUDA 里,程序不是直接说“让 GPU 帮我算”。
它会把任务切成很多层:
Grid
├── Block
│ ├── Thread
│ ├── Thread
│ └── ...
├── Block
└── ...
一个 CUDA kernel 启动时,通常会写成:
kernel<<<blocks, threads>>>();
比如:
vectorAdd<<<4, 256>>>();
意思是:
启动 4 个 block
每个 block 有 256 个 thread
而 GPU 硬件里真正执行计算的是 SM,也就是 Streaming Multiprocessor。
可以简单理解成:
GPU = 很多个 SM
SM = 一个小型计算工厂
CUDA block 会被调度到 SM 上执行。
一个 block 不会跨多个 SM。
但一个 SM 可以同时驻留多个 block,并在这些 block 的 warp 之间切换执行。
这里还有一个重要概念:warp。
1 warp = 32 个线程
GPU 实际调度时,不是一个线程一个线程调度,而是按 warp 调度。
所以可以这样理解:
Block 被分配到 SM
Block 里的 Thread 被分成 Warp
SM 实际调度 Warp 执行
八、最直接的矩阵乘法为什么不够快?
最直接的矩阵乘法代码是这样的:
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
for (int k = 0; k < K; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
这个写法很直观。
但在 GPU 上,真正的问题不只是“要算多少次乘加”。
还有一个更重要的问题:
数据从哪里来?
数据要搬多少次?
数据能不能被复用?
GPU 上的 global memory,也就是显存,容量很大,但访问速度相对慢。
而 SM 内部的 shared memory 很快,但容量很小。
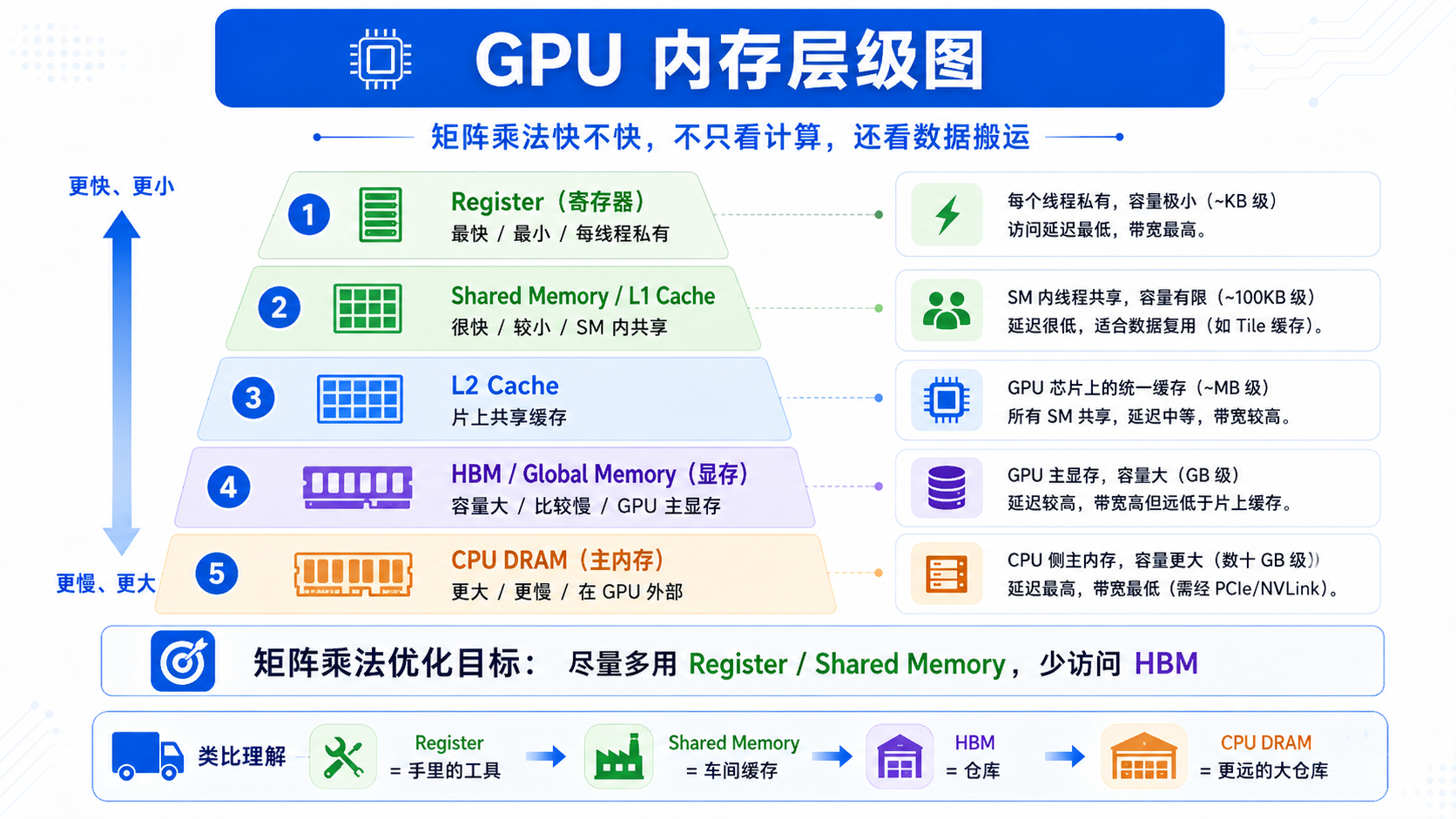
如果每个线程都反复从 global memory 读取 A 和 B 的元素,性能会被内存访问拖慢。
所以 CUDA 优化矩阵乘法时,经常会使用一个核心技巧:
Tile 分块计算
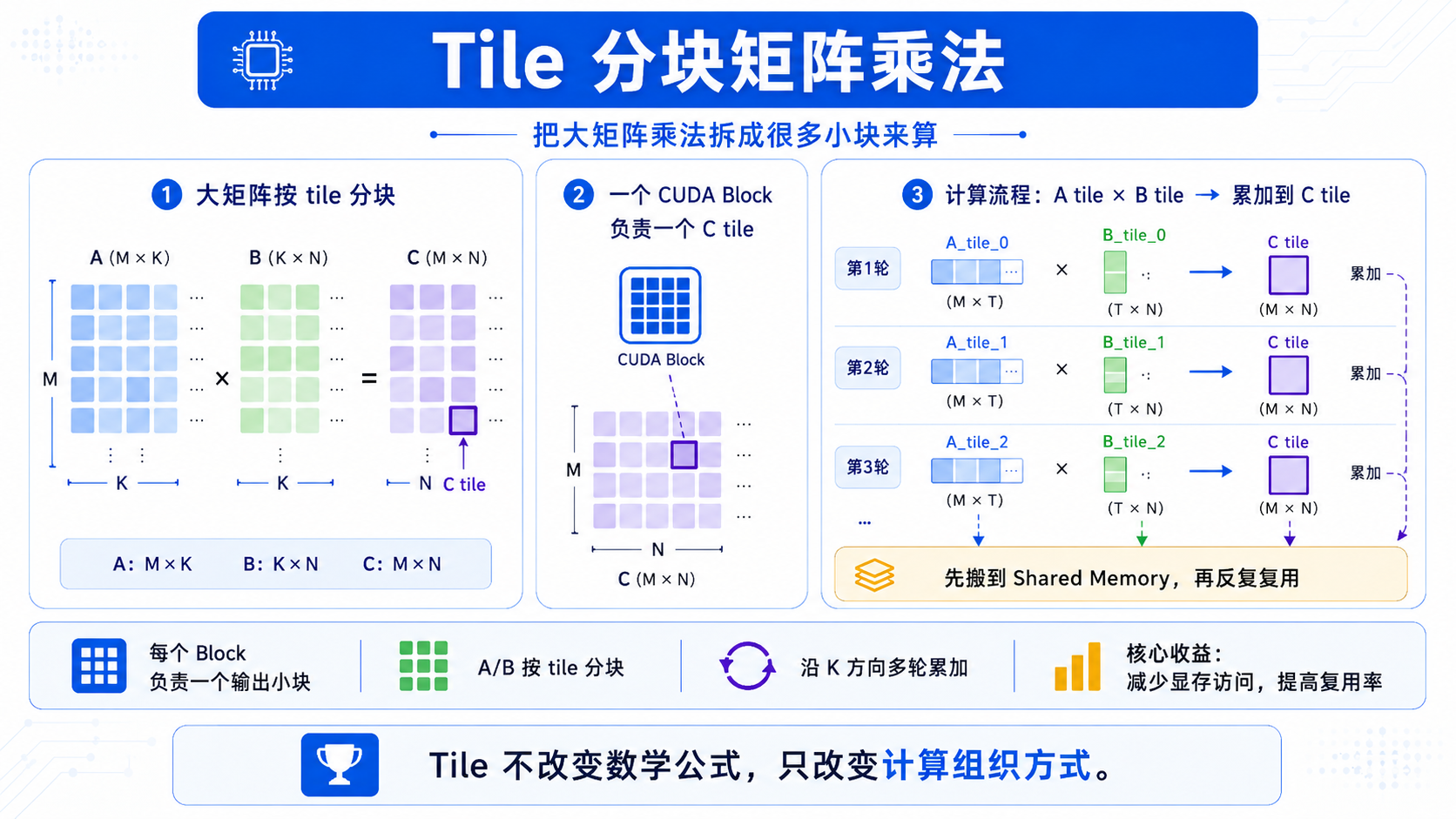
九、什么是 Tile 分块?
假设要计算:
C = A × B
我们不一次性处理整个大矩阵,而是把矩阵切成很多小块。
比如把 C 切成 16×16 的小块:
C tile = 16 × 16
每个 CUDA block 负责计算 C 的一个小块。
为了算出这个 C tile,需要从 A 中取一块,从 B 中取一块:
A tile × B tile → 累加到 C tile
如果 K 维很长,就沿着 K 方向一块一块推进:
第 1 轮:A_tile_0 × B_tile_0
第 2 轮:A_tile_1 × B_tile_1
第 3 轮:A_tile_2 × B_tile_2
...
最后累加得到 C tile。
所以 Tile 优化的核心思想是:
先把 A、B 的小块搬到 shared memory,
然后 block 内的线程反复复用这些数据,
从而减少对 global memory 的访问。
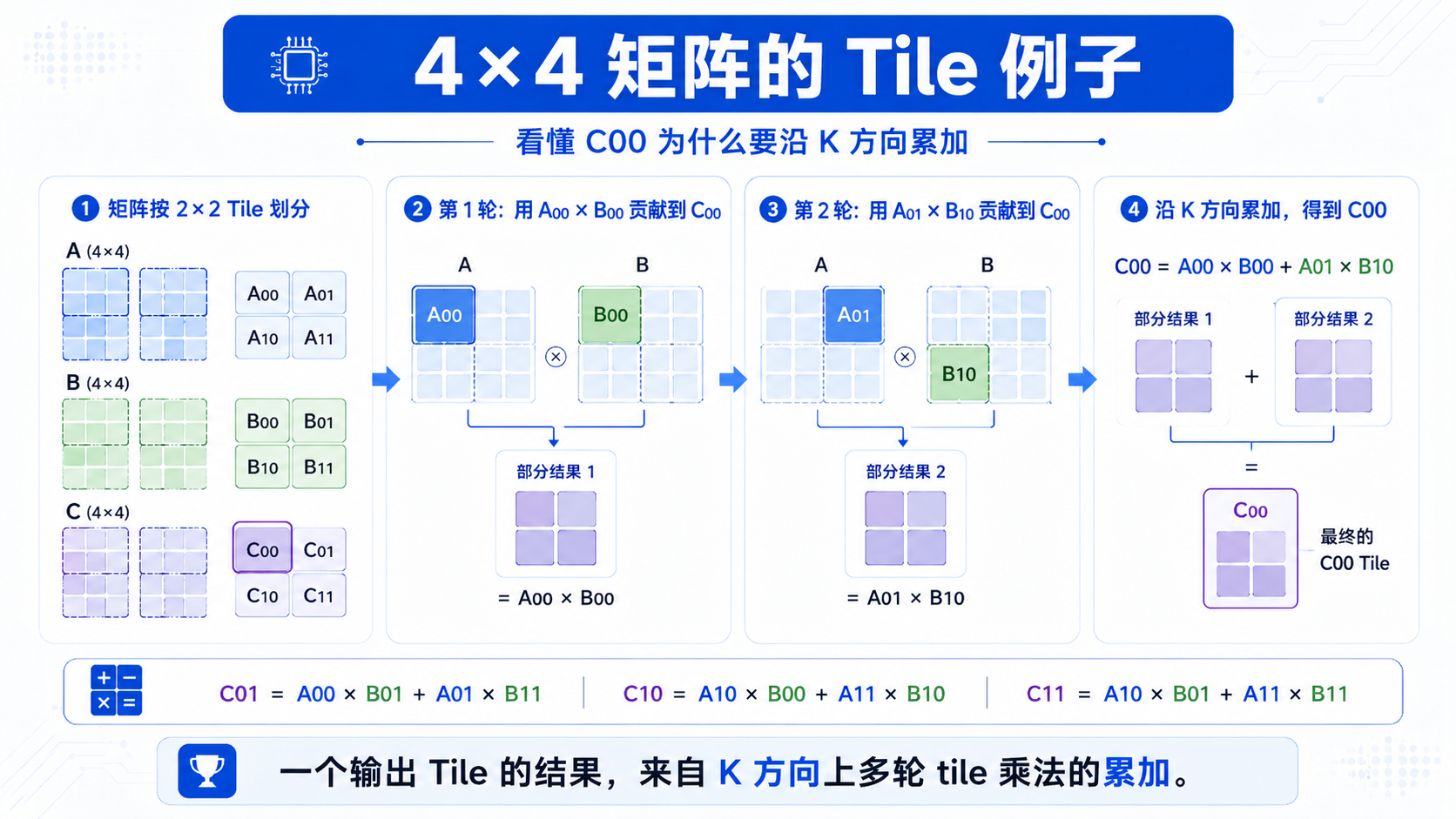
十、一个 4×4 的直观例子
假设:
A: 4 × 4
B: 4 × 4
C: 4 × 4
我们把 tile 大小设成 2×2。
那么 C 会被分成 4 个小块:
C00 C01
C10 C11
其中 C00 是左上角的 2×2 小矩阵。
为了计算 C00,需要:
A 的前 2 行
B 的前 2 列
但矩阵乘法还要沿着 K 方向累加。
所以 C00 的计算过程是:
第一轮:
A00 × B00
第二轮:
A01 × B10
两轮结果累加,得到:
C00 = A00 × B00 + A01 × B10
同理:
C01 = A00 × B01 + A01 × B11
C10 = A10 × B00 + A11 × B10
C11 = A10 × B01 + A11 × B11
也就是说:
不是 A 的一个 tile 只和 B 的一个 tile 相乘,
而是 A 沿 K 方向的多个 tile,
要依次和 B 对应位置的多个 tile 相乘,
最后把结果累加起来。
十一、为什么 Tile 能提升性能?
Tile 优化的核心不是减少数学计算量。
矩阵乘法该做多少乘加,还是要做多少乘加。
它真正优化的是:
减少慢速内存访问
提高数据复用率
让更多线程并行工作
比如 A 的一个 tile 被加载到 shared memory 后,block 内多个线程都会反复使用它。
B 的 tile 也是一样。
这样就避免了每个线程都重复从 global memory 读取同样的数据。
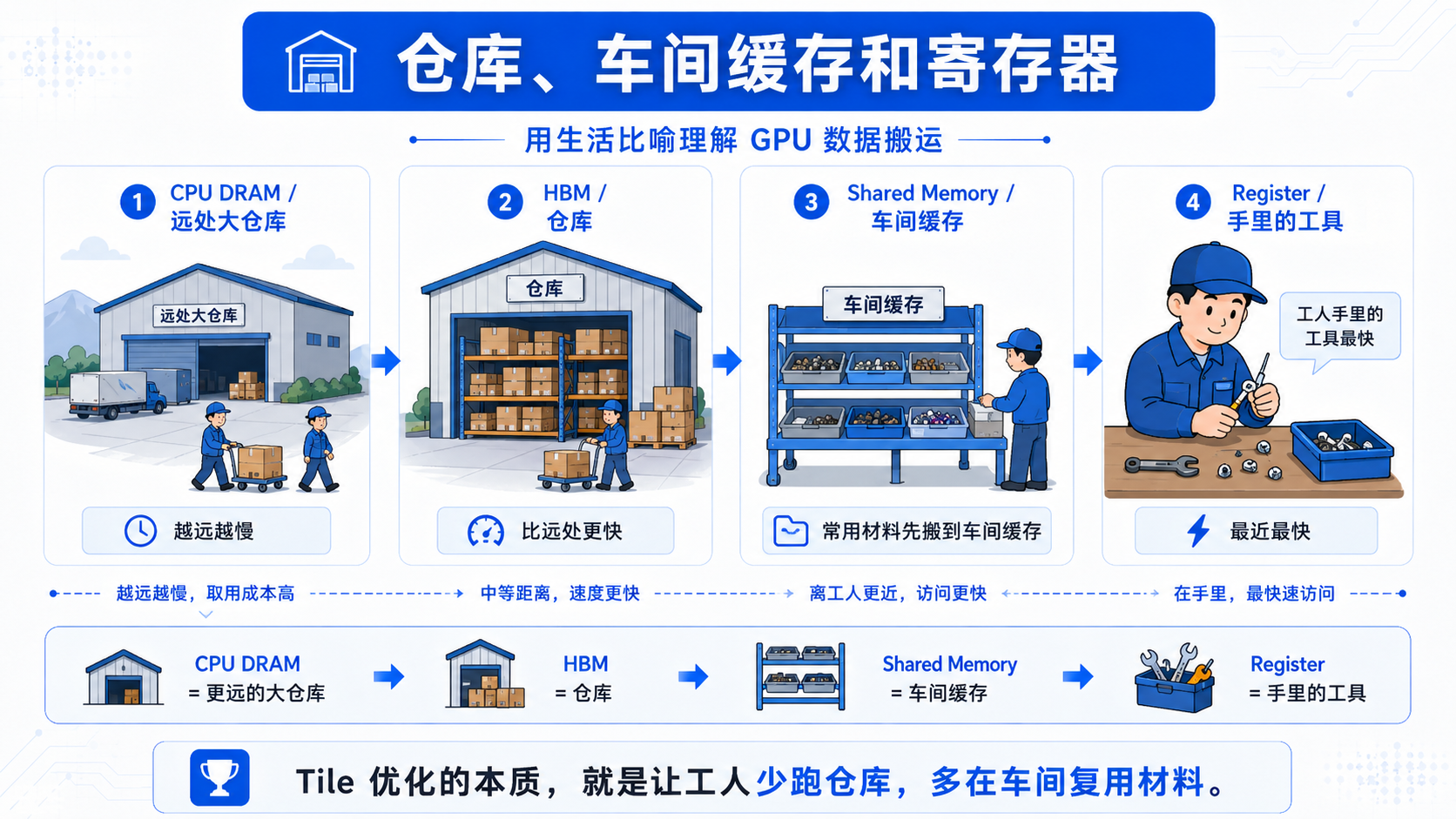
可以把它理解成:
global memory:仓库,很大但取货慢
shared memory:车间缓存,很小但取货快
register:手里正在用的工具,最快但最小
Tile 优化就是:
先把常用材料从仓库搬到车间,
大家在车间里反复使用,
不用每算一步都跑回仓库。
这就是 GPU 优化里非常重要的思想:
数学公式没有变,
但计算组织方式变了。
十二、从 Tile 到 FlashAttention
回到大模型。
大模型中的 Attention、MLP、Embedding 投影、输出投影,背后都有大量矩阵乘法。
训练时的梯度计算,同样是大量矩阵乘法。
所以大模型的性能,很大程度取决于:
矩阵乘法算得够不够快
显存访问够不够高效
并行度够不够高
GPU 利用率够不够满
CUDA、cuBLAS、Tensor Core、FlashAttention、PagedAttention 等优化,本质上都在围绕这些问题展开。
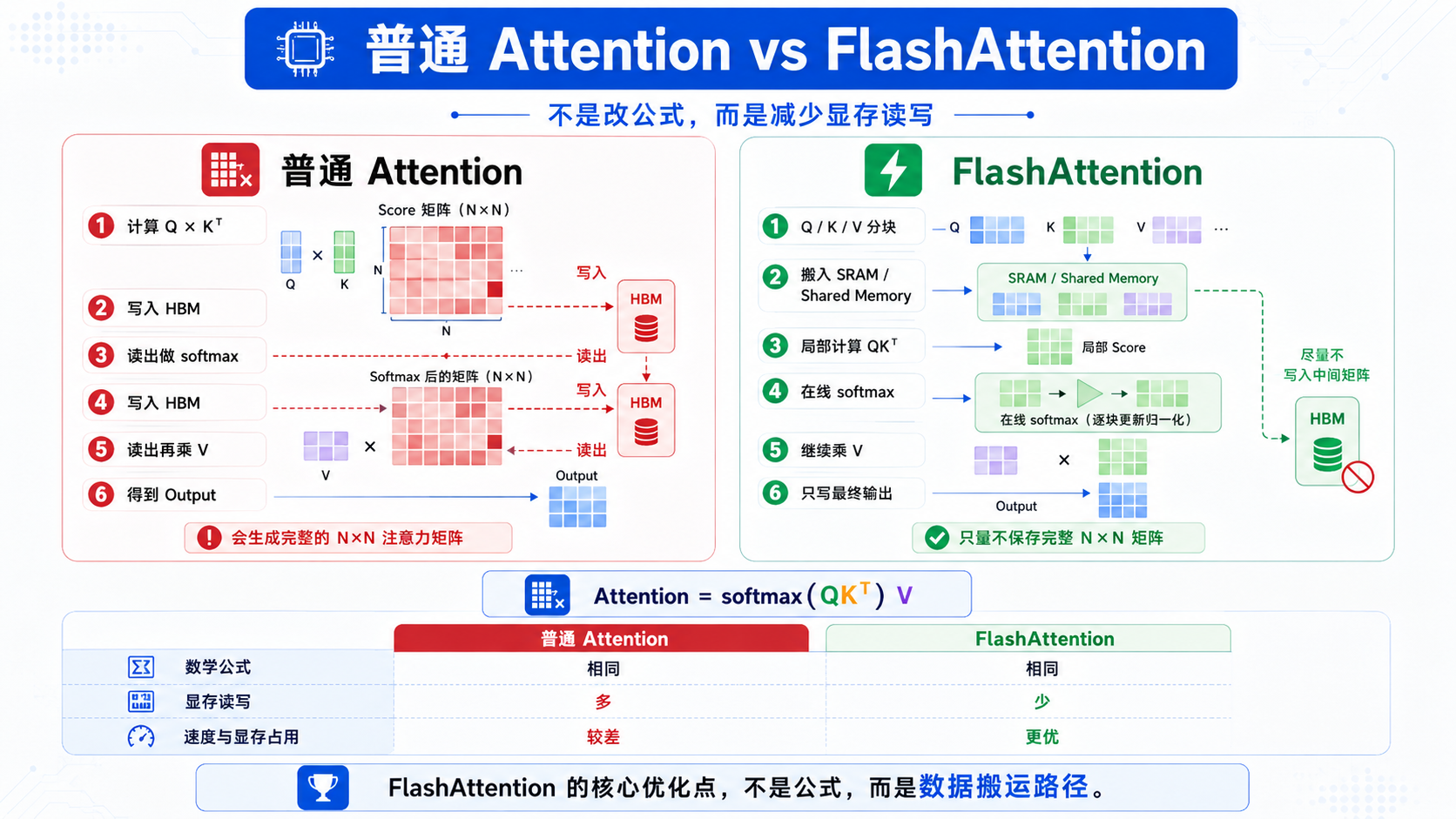
比如 FlashAttention 不是改变 Attention 的数学公式。
Attention 还是:
softmax(QKᵀ)V
但普通 Attention 可能会把完整的 QKᵀ 注意力矩阵写到显存里,再读出来做 softmax,再写回,再读出来乘 V。
这样会产生大量 HBM 显存读写。
FlashAttention 的核心思路是:
把 Q、K、V 分块
在 SRAM / shared memory 中局部计算
一边做 softmax
一边乘 V
尽量不保存完整的 N×N 注意力矩阵
也就是说:
数学公式没有变,
但数据搬运路径变了。
这和 Tile 矩阵乘法的思想非常像。
十三、总结
现代 AI 模型看起来非常复杂。
但从计算角度看,它的核心可以总结为一句话:
大模型 = 海量参数矩阵 + 大规模矩阵运算 + GPU 并行优化
LLM 前向传播时:
Attention 是矩阵运算
MLP 是矩阵运算
Linear 投影是矩阵运算
训练反向传播时:
梯度计算还是矩阵运算
参数更新也是围绕矩阵进行
而 GPU / CUDA 的作用,就是把这些矩阵运算切分成大量小任务,让成千上万个线程一起并行计算。
所以理解大模型计算,矩阵乘法是第一步。
理解 GPU 加速,Tile 分块是第一步。
如果你再继续往下看,就会发现:
Tensor Core 是为了更快地算矩阵乘法;
cuBLAS 是高度优化的矩阵乘法库;
FlashAttention 是 Attention 里的分块计算优化;
PagedAttention 是 KV Cache 管理上的内存优化。
很多看似高级的 AI 系统优化,背后其实都绕不开同一个问题:
怎么算得更快?
怎么少搬数据?
怎么把 GPU 喂饱?
大模型看起来像是在“理解语言”。
但从硬件视角看,它其实是在一层又一层地做矩阵乘法。
智能的表象背后,是海量矩阵、海量数据搬运,以及 GPU 上成千上万个线程的并行计算。
当你真正理解了矩阵乘法,你就已经摸到了现代 AI 计算的地基。
当你真正理解了 Tile 分块,你就已经拿到了理解 GPU 加速的第一把钥匙。