计算机基本架构-中央处理器
计算机基本架构-中央处理器
本章介绍一个基本的中央处理单元(CPU),其操作采用简化的精简指令集(RISC)。本章分为四个部分。
第一部分介绍了定点指令(fixed-point instruction)。该部分首先开发专用硬件(数据通路)来执行单个RISC指令,然后将多条指令组合成一个集合,并设计一个通用数据通路,以便执行使用该指令集的用户程序。在过程的每一步中,指令字段被划分成几个段,随着指令通过数据通路,必要的硬件被形成以执行指令并生成输出。在这一部分,描述了与定点相关的结构性、数据和程序控制冒险(hazard),并解释了如何防止每种类型的冒险的方法。
本章的第二部分专门讨论IEEE单精度和双精度浮点格式,并引出简化的浮点加法器和乘法器设计。然后,这些设计与定点硬件集成,以获得能够执行定点和浮点算术指令的RISC CPU。在同一部分中,还描述了与浮点相关的数据冒险。为了减少和消除这些冒险,提出了一种基于简化的Tomasula算法的新浮点架构。
在第三部分中,讨论了提高程序执行效率的各种技术。通过示例解释了静态和动态流水线、单发射与双发射和三发射流水线之间的权衡。编译器增强技术,如循环展开和动态分支预测方法,也被介绍以减少整体CPU执行时间。
本章的最后一部分解释了不同类型的缓存内存架构,包括直接映射、组相联和全相联缓存,它们的操作以及每种缓存结构之间的权衡。还讨论了直写和回写机制,并通过各种设计示例对它们进行比较。
1.定点单元
指令集格式
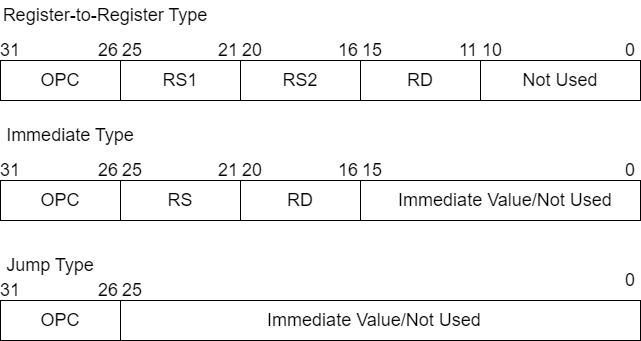
在RISC CPU中,所有指令都包含一个操作码(OPC)字段,该字段指示处理器如何处理指令中的其余字段,以及何时激活CPU中的不同硬件组件以执行指令。OPC字段后面是一个或多个操作数字段。每个字段要么对应于寄存器文件(RF)中的一个寄存器地址,要么包含用于处理指令的立即数数据。
RISC CPU中有三种类型的指令:寄存器到寄存器类型、立即数类型和跳转类型。
寄存器到寄存器类型的指令包含一个操作码(OPC),后面是三个操作数:两个源寄存器地址和一个指向寄存器文件(RF)的目标寄存器地址,分别是RS1、RS2和RD。该指令的格式如下所示:
OPC RS1, RS2, RD
这种类型的指令从寄存器文件(RF)中获取第一个和第二个源寄存器的内容,分别是Reg[RS1]和Reg[RS2],根据操作码(OPC)对它们进行处理,并将结果写入目标寄存器Reg[RD]中。该操作如下所述。
Reg[RS1] (OPC) Reg[RS2] -> Reg[RD]
一个立即数类型的指令包含一个操作码(OPC)和三个操作数:一个源寄存器地址RS,一个目的寄存器地址RD,以及一个立即数据,如下所示:
OPC RS, RD, Imm Value
这种类型的指令将源寄存器Reg[RS]的内容与根据操作码(OPC)进行符号扩展的立即值相结合,然后将结果写入寄存器文件中的目的寄存器Reg[RD]。该操作如下所示:
Reg[RS] (OPC) Immediate Value -> Reg[RD]
Jump-type指令包含一个操作码(OPC),后面跟着一个单独的立即值,如下所示。
OPC Imm Value
这种类型的指令使用立即字段来修改指令存储器中的程序计数器(PC)内容。该指令的操作如下所示。
Immediate Value -> PC
所有三种指令类型都适合于一个32位宽的指令存储器,如图6-1所示。在这张图中,每个字段顶部的数字对应于指令存储器的位位置,定义了操作码(OPC)或特定操作数字段的边界。
CPU数据路径
现代RISC CPU由算术逻辑单元(ALU)组成,用于执行操作数;有寄存器(RF)形式的小型内存,用于存储临时数据;以及两块大容量缓存,分别作为指令缓存和数据缓存。程序计数器(PC)在指令存储器中为每条指令生成指令内存地址,如图2所示。每条指令都从这个存储器中获取,并分离为操作码(OPC)和操作数字段。操作码(OPC)字段指导数据流经过CPU的其余部分。操作数字段包含一系列寄存器(RF)地址或用户数据,或两者的组合。一旦源地址和目标地址在指令存储器的输出端可用,相应的数据就会从寄存器文件(RF)中获取,并根据操作码(OPC)在算术逻辑单元(ALU)中进行处理。处理后的数据随后被写回到寄存器文件(RF)的目标地址。另一方面,如果特定指令需要从数据存储器而不是寄存器文件(RF)中获取数据,则算术逻辑单元(ALU)会计算数据存储器的有效内存地址。当数据从数据存储器输出可用时,它会被路由回到寄存器文件(RF)中的目标地址。有时,指令包含用户定义的立即数值。这些立即数值从操作数字段的其余部分分离出来,并与ALU中的源寄存器Reg[RS]的内容结合。处理后的数据随后被写回到寄存器文件(RF)。
图2
在RISC CPU中,指令可以以两种方式执行。在非流水线CPU架构中,指令从指令存储器中获取,并在图2中CPU的其余四个阶段中进行处理,然后CPU才会获取下一条指令。这在图3中有所展示。在该图中,IF对应指令获取阶段(Instruction Fetch stage),RF对应寄存器文件阶段(Register File stage),A对应ALU阶段,DM对应数据存储器阶段,最后WB对应写回阶段(Write-Back stage)。
图3
非流水线结构在数据吞吐量方面效率低下,但需要更低的时钟频率来运行。如果根据图2的架构将CPU细分为更小的功能阶段,并且每个阶段都通过一个触发器边界与其相邻阶段分离,只存储数据(或地址)一个时钟周期,那么CPU在吞吐量方面将变得更加高效,如图4所示。在这个图中,CPU数据路径包括五个阶段,每个阶段内的个别任务在一个时钟周期内执行。根据这种方案,时钟频率比图2中的架构高出五倍。
图4
在图4中这个新流水线的第一阶段是指令存储器访问,如前所述。在这个阶段,每条程序指令从指令存储器中获取,并存储在第一个触发器边界处的指令寄存器中。这种架构支持字寻址的指令存储器,因此需要程序计数器(PC)递增一。
接下来的流水线阶段是RF阶段,其中指令的操作码(OPC)与操作数分离。操作码(OPC)被解码,以生成控制信号,用于在CPU的其余部分中路由地址和数据。操作数字段可以是用于访问RF中数据的源寄存器地址,也可以是用户提供的立即数据,如前所述。如果操作数对应于RF地址,则从该地址获取的数据加载到位于第二触发器边界处的寄存器中。如果操作数是一个立即数,则在加载到第二触发器边界处的寄存器之前,它将被符号扩展为32位。
CPU流水线的第三阶段是ALU阶段。在这个阶段,来自RF中源寄存器或立即数据的数据根据操作码(OPC)进行处理,并加载到位于第三触发器边界处的寄存器中。
第四阶段是数据存储器阶段。在这个阶段,CPU访问数据存储器的内容,或完全绕过数据存储器。如果指令需要进行加载或存储操作,ALU会计算数据存储器的地址以访问其内容。否则,ALU的结果会直接绕过数据存储器,并存储在第四个触发器边界处。
CPU流水线的最后一个阶段是写回阶段。在这个阶段,数据要么从数据存储器的输出路由,要么从旁路路径路由到RF中的指定目标地址。
图5中的时序表显示了流水线化RISC CPU的效率和速度。这个图表延伸到了15个高频时钟周期,相当于图3中的三个低频时钟周期。在这个新流水线中,完成的指令数接近12条,比图3中的指令数多了四倍。非流水线和流水线CPU效率的差异随着指令数量的增加而变得更加明显。
图5
本章的下一部分将讨论寄存器到寄存器类型、立即数类型和跳转类型的RISC指令的硬件要求。
寄存器到寄存器类型的ALU指令
寄存器到寄存器类型的ALU指令仅与ALU进行交互。这一类别中最基本的指令是Add(ADD)指令,包含ADD操作码、两个源寄存器地址RS1和RS2,以及一个目标寄存器地址RD,如下所示:
ADD RS1, RS2, RD
该指令从源地址RS1和RS2中获取数据,将它们相加,并将结果返回到目标地址RD,如下方的方程所示。
Reg[RS1] + Reg[RS2] -> Reg[RD]
这条指令在指令存储器中的字段格式如图6所示。每个字段顶部的数字表示操作码(OPC)和操作数的位边界。
图6
ADD指令所需的硬件如图7所示