介绍一个超直观的 Token 可视化工具:Tiktokenizer
category:
- AI tag:
- 人工智能
介绍一个超直观的 Token 可视化工具:Tiktokenizer
很多人刚开始学习大模型时,都会默认一个理解:
我们输入一段文字,GPT 就是在“读”这段文字。
比如你问它:
What is c plus plus
从人的角度看,这就是一句普通的问题。
但从模型的角度看,事情并没有这么简单。
GPT 并不是直接处理原始文字。
在文字真正进入模型之前,会先经过一个非常关键的步骤:
Tokenization,也就是分词。
简单来说,Tokenizer 会先把文本切成一个个 Token,然后再把每个 Token 转换成对应的数字编号,也就是 Token ID。
模型真正处理的,并不是我们肉眼看到的文字,而是 Token ID 经过 Embedding 层映射出来的向量。
整个过程可以简单理解为:
人类输入的文字
↓
Tokenizer 切分成 Token
↓
Token 转换成 Token ID
↓
Embedding 转换成向量
↓
送入 Transformer 模型计算
这个过程听起来有点抽象,所以今天介绍一个非常直观的工具:Tiktokenizer。
它可以把 GPT 的分词过程可视化出来,让我们看到一段文本在进入模型之前,究竟被拆成了什么样子。
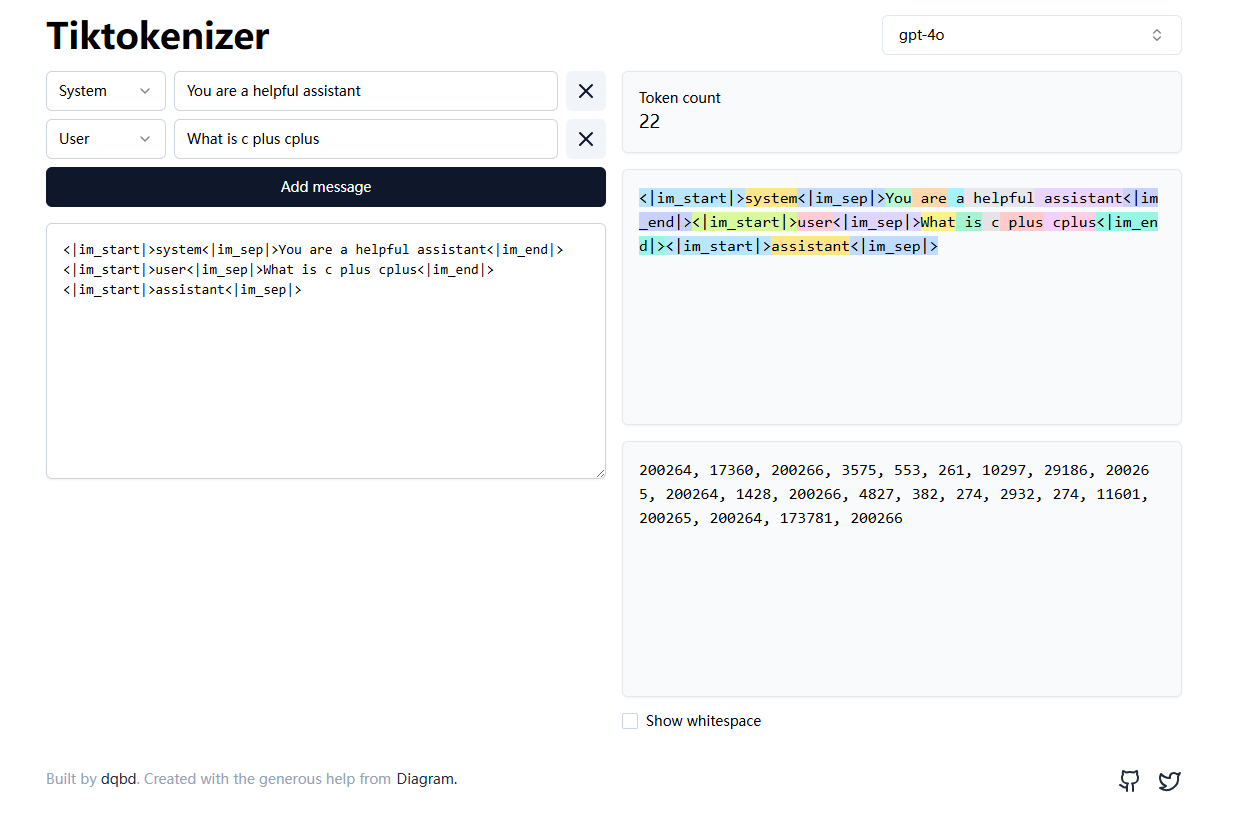
在图中,选择的是 gpt-4o 模型,输入了两条消息:
System: You are a helpful assistant
User: What is c plus plus
从人的角度看,这只是两句很短的话。
但在 Tiktokenizer 里可以看到,它并不是被简单地当成普通文本处理,而是被转换成了一段带有聊天结构的 Token 序列。
里面不仅包含我们输入的文字,还包含一些特殊标记,例如:
<|im_start|>
<|im_sep|>
<|im_end|>
这些特殊标记用来表示消息开始、角色分隔、消息结束等结构信息。
也就是说,GPT 看到的并不只是:
What is c plus plus
而是一个包含 system、user、assistant 角色结构 的完整输入序列。
这也是很多人容易忽略的一点:
ChatGPT 的输入,不只是你打进去的那句话,还包括角色、分隔符、历史消息和上下文结构。
图里最直观的地方,是右侧那一串彩色的小块。
每一个颜色块都代表一个被切分出来的 Token。
下方那一串数字,则是这些 Token 对应的 Token ID。
也就是说,我们输入的文字并不会直接进入模型,而是会先被 tokenizer 拆分、编号,再交给后面的 embedding 层转换成向量。
这也是理解大模型输入机制时很关键的一点:
模型看到的不是“文字”,而是由 Token ID 转换而来的向量。
所以,Tokenizer 不只是“把文字切开”,它更像是大模型输入层的第一道转换器:
把人类能读懂的文本,转换成模型能计算的数字序列。
除了查看分词结果,Tiktokenizer 还有一个很实用的功能:可以切换不同模型或编码器。
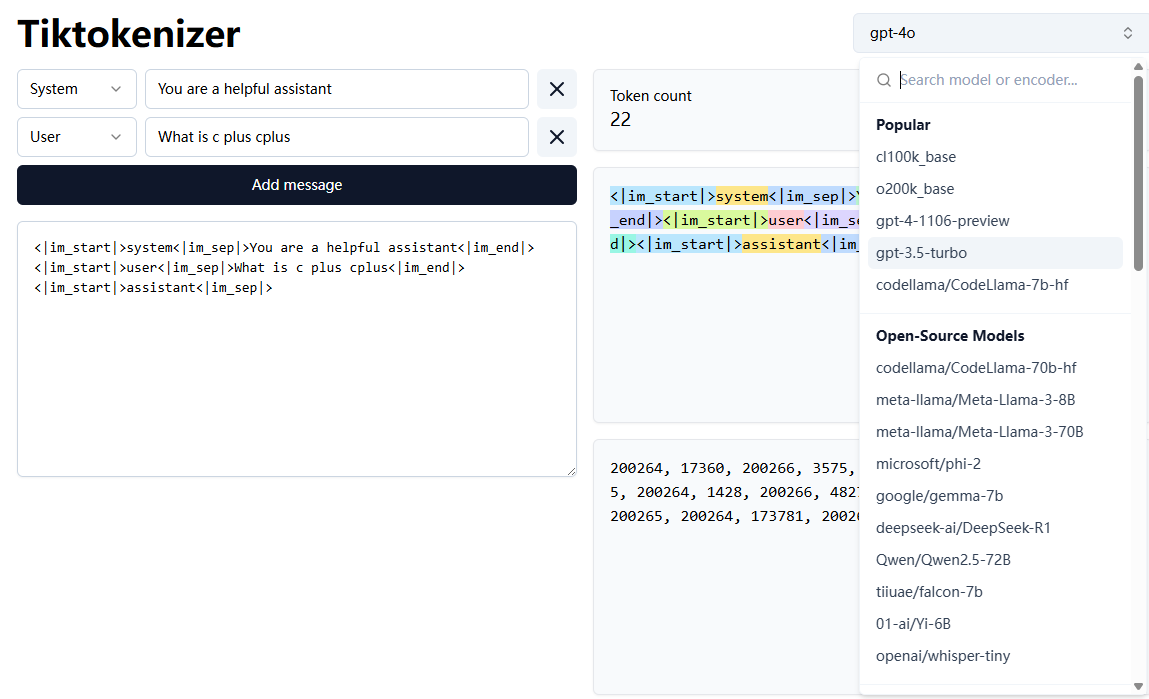
在右上角的下拉框里,可以看到很多模型或编码器选项,比如:
gpt-4o
gpt-4-1106-preview
gpt-3.5-turbo
cl100k_base
o200k_base
DeepSeek-R1
Qwen2.5-72B
Llama-3
CodeLlama
这个功能很有用。
因为不同模型使用的 tokenizer 可能不同。
同一段文本,放到不同模型下,切出来的 Token 数量和 Token ID 都可能不一样。
比如中文、英文、代码、JSON、Markdown,这些内容在不同 tokenizer 下的切分方式可能会有明显差异。
这也是为什么我们不能简单地用“字数”来估算大模型输入长度。
对大模型来说,真正重要的不是字符数,而是 Token 数。
理解 Tokenizer 之后,很多大模型相关问题都会变得更清楚。
比如,为什么 Prompt 越长,调用成本越高?
因为模型处理的是 Token。输入 Token 越多,通常意味着计算成本越高。
为什么上下文窗口有限?
因为所谓的 8K、32K、128K 上下文,本质上指的是模型最多能处理多少 Token,而不是多少个中文字或英文单词。
为什么做 RAG、Agent、多轮对话时要控制上下文长度?
因为系统提示词、历史对话、检索内容、工具返回结果,都会一起占用 Token 空间。
如果 Token 太多,就会挤占上下文窗口,甚至导致关键信息被截断。
所以,Tiktokenizer 不是一个简单的“数字数工具”。
它更像是一个帮助我们理解大模型输入机制的可视化窗口。
你可以用它做几个小实验:
把一段中文放进去,看它被切成多少 Token。
把一段英文放进去,对比单词数和 Token 数。
把一段代码放进去,观察空格、缩进、符号会不会占 Token。
切换不同模型,比较同一段文本的分词差异。
把自己的 Prompt 放进去,看看实际消耗了多少 Token。
当你真正看过 Tokenizer 的结果之后,就会明白一句话:
人类看到的是文字,模型看到的是 Token。
而 Tiktokenizer,就是一个帮我们看见 GPT 输入世界的小工具。